London Train Network#
Author: Lucy Wu
Definitions#
Nodes: (369 nodes) Each node represents a different station in the London train network (see further classifications below)
Edges: (441 edges) Each edge represents a connection between one station to another
Layers: (1-3) Each node is assigned to a corresponding layer of the train network
Underground (The Tube)
Overground
DLR (Docklands Light Railway, automated light metro system)
Undirected: It is possible to travel back and forth between two stations
Weights: (1-3) Represent the number of different lines connecting two stations (applies to only Underground)\
Citations#
Original Dataset: https://networks.skewed.de/net/london_transport
Paper: De Domenico, Manlio, et al. “Navigability of Interconnected Networks under Random Failures.” Proceedings of the National Academy of Sciences, vol. 111, no. 23, June 2014, pp. 8351–56. DOI.org (Crossref), https://doi.org/10.1073/pnas.1318469111.
#Importing packages
import csv
import networkx as nx
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import graspologic as gs
Adjusting My Data#
To the original nodes file, I added in another column to collect Fare Zone information. I felt this would be a good way to make my insights more interesting.
Importing the Data#
#Importing the nodes
#Note: We can only use hashable data types, so we must use tuples
with open(r'/Users/lucywu/london_transport_network/london_nodes.csv', 'r') as london_node_csv:
node_reader = csv.reader(london_node_csv)
nodes = []
node_dict = {}
node_fare = []
node_fare_dict = {}
node_pos_dict = {}
#Skip over the header
next(node_reader, None)
#Iterate over each row to get all nodes
for row in node_reader:
nodes.append(int(row[0]))
#Make a dictionary of the nodes and their names (we will use it for attributes later)
node_dict[int(row[0])] = row[1]
#Make a dictionary of the nodes and their zone fares
node_fare_dict[int(row[0])] = row[3]
node_fare.append(float(row[3]))
#Make a dictionary of the nodes and their positions
node_pos_dict[int(row[0])] = row[6]
#Change list into tuple so it's hashable
t_nodes = (tuple(nodes))
#Importing the edges
with open(r'/Users/lucywu/london_transport_network/london_edges.csv', 'r') as london_edge_csv:
edge_reader = csv.reader(london_edge_csv)
edges = []
edge_weight = {}
edge_layer = {}
next(edge_reader, None)
for row in edge_reader:
#Store the first two columns of data, which correspond to the source (origin) and target (destination)
edges.append([int(row[0]), int(row[1])])
#Make a dictionary of edges and their weight (keyed by each edge tuple)
#Also make sure that weight is numeric because it will be used by other algorithms
edge_weight[tuple([int(row[0]), int(row[1])])] = int(row[2])
#Make a dictionary of edges and their weight (keyed by each edge tuple)
edge_layer[tuple([int(row[0]), int(row[1])])] = int(row[3])
#Change list into tuple so it's hashable
t_edges = (tuple(edges))
#Making a pandas dataframe for later use
data_path = r'/Users/lucywu/london_transport_network/london_nodes.csv'
node_data = pd.read_csv(data_path, index_col=0)
#Make a dictionary keyed by node with values from a tuple of our longitude (x) and latitude (y) for our node positions
node_pos = dict(zip(node_data.index, list(zip(node_data[' nodeLong'], node_data[' nodeLat']))))
For now, I am considering a top down view of the transportation network, meaning I am not considering which layer each edge belongs to. We will explore this important feature later.
#Make an undirected graph
G = nx.Graph()
#Add nodes
G.add_nodes_from(t_nodes)
#Add edges
G.add_edges_from(t_edges)
#Double check the information is correct
print(nx.info(G))
Graph with 369 nodes and 430 edges
/var/folders/66/7hvj9wvn2yj3mtg3bd4w8tjh0000gn/T/ipykernel_85898/4078871977.py:11: DeprecationWarning: info is deprecated and will be removed in version 3.0.
print(nx.info(G))
Note that there are some edges missing because we have not yet considered our layer data yet, so two edges that exist on different layers are treated as only one edge so far. We will fix this later with MultiGraph!
#Let's try printing an array to see what's happening?
#Take out the nodes from the networkx graph
nodelist_G = list(G.nodes)
A = nx.to_numpy_array(G, nodelist=nodelist_G)
A
array([[0., 1., 0., ..., 0., 0., 0.],
[1., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 1.],
[0., 0., 0., ..., 0., 1., 0.]])
#We can also try a heatmap with seaborn
sns.heatmap(A)
<AxesSubplot: >
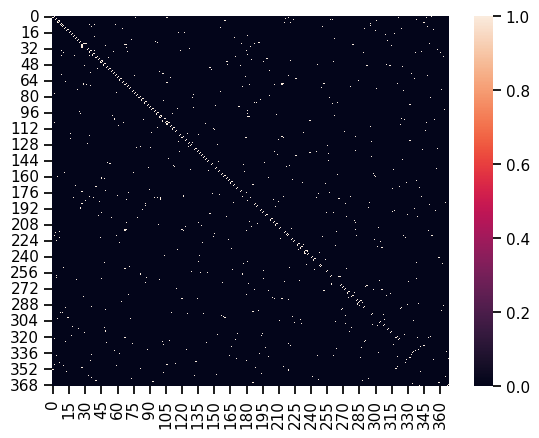
This is a pretty sparse array, but it makes sense because every station most likely does not connect to hundreds of other stations. Observe how many of the connections (white squares) are clustered around the diagonal. This depends on how the data is sorted, but it would make sense in this case because a station is connected to the one directly before and after it. The graph is also symmetric because it is undirected. Also note that we still have not considered weight or layer data, so this is a top down view.
#Drawing the network
#This is pretty ugly, this helps with formatting so it looks less like a spider...
#I artificially scaled the figure size to try and make it as geographically close to the actual London transport network as possible
fig, ax = plt.subplots(1, 1, figsize=(20,12))
#Adding some more parameters to make it readable
nx.draw_networkx(G, pos=node_pos, node_size=25, labels=node_dict, font_size=5, ax=ax)

Node Attributes#
We should consider some limitations that will make our data more interesting to interpret.
Since there are multiple layers to the train network, we should consider the layer number of each. We should also add in the weight, since it may help inform certain underground stations that are more densely connected than others. Lastly, we will add in the node names so we can reference which station is tied to which node.
#Set node attributes
nx.set_node_attributes(G, node_dict, 'station_name')
nx.set_node_attributes(G, node_fare_dict, 'fare_zone')
#Set edge attributes
nx.set_edge_attributes(G, edge_weight, 'weight')
nx.set_edge_attributes(G, edge_layer, 'layer')
Because our previous network excluded 11 edges since the same nodes were repeated, we need to make a multigraph if we want to preserve our edge data without it being overwritten.
#Multigraph fixes a lot of issues and we can include all 441 edges now
M = nx.MultiGraph()
M.add_nodes_from(t_nodes)
M.add_edges_from(edges)
#Add in attributes again but this time keyed to edge tuples with all 441 edges
#Set node attributes the same way as before
nx.set_node_attributes(M, node_dict, 'station_name')
nx.set_node_attributes(M, node_fare_dict, 'fare_zone')
#Create edge attributes lists
edge_weight_M = []
edge_layer_M = []
with open(r'/Users/lucywu/london_transport_network/london_edges.csv', 'r') as london_edge_csv:
edge_reader = csv.reader(london_edge_csv)
next(edge_reader, None)
for row in edge_reader:
edge_weight_M.append({'weight': int(row[2])})
edge_layer_M.append({'layer': int(row[3])})
#Make the dictionaries by joining the two lists
edge_weight_d = dict(zip(M.edges, edge_weight_M))
edge_layer_d = dict(zip(M.edges, edge_layer_M))
#Set the multigraph edge attributes
nx.set_edge_attributes(M, edge_weight_d)
nx.set_edge_attributes(M, edge_layer_d)
#Now we have the correct number of nodes and edges!
print(nx.info(M))
MultiGraph with 369 nodes and 441 edges
/var/folders/66/7hvj9wvn2yj3mtg3bd4w8tjh0000gn/T/ipykernel_85898/229748201.py:32: DeprecationWarning: info is deprecated and will be removed in version 3.0.
print(nx.info(M))
#Let's look at an array and heatmap of the multigraph instead
nodelist_M = list(M.nodes)
B = nx.to_numpy_array(M, nodelist=nodelist_M)
print(B)
sns.heatmap(B)
#Double check that the graph is symmetric
from graspologic.utils import is_symmetric
print(is_symmetric(B))
[[0. 1. 0. ... 0. 0. 0.]
[1. 0. 0. ... 0. 0. 0.]
[0. 0. 0. ... 0. 0. 0.]
...
[0. 0. 0. ... 0. 0. 0.]
[0. 0. 0. ... 0. 0. 1.]
[0. 0. 0. ... 0. 1. 0.]]
True
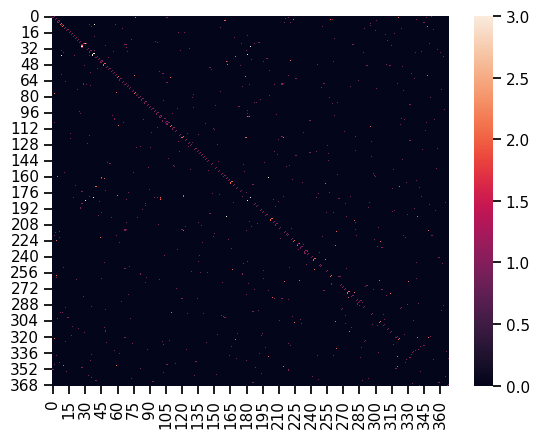
With multigraph: a white square means that an edge exists on multiple layers. It’s fairly obvious that there are very few nodes that have edges which exist on multiple layers.
Coloring the Nodes#
In London, the fare system is based on which zone you travel from, and which zone you are travelling to. It is shaped similar to a bullseye or oyster (hence the Oyster Card payment system) so that the nexus is Zone 1 and the outskirts of London are Zone 9 and beyond. Interestingly, there are also half zones, so in that instance, I used .5 as a way to quantify these zones.
#Coloring by fare zone
#Make a dataframe of fare zones
node_list = M.nodes
colors_dict = pd.DataFrame({
'Index' : node_list,
'Fare Zone' : node_fare
})
#Generate colors based on the number of unique fare zones
#I chose the 'hls' system because it provided the most contrast and thus made the zones the most visible
colors = sns.color_palette('hls', colors_dict['Fare Zone'].nunique())
#Make a color palette dictionary
palette = dict(zip(sorted(colors_dict['Fare Zone'].unique()), colors))
#Map colors to node and update the color attribute
colors_dict['color'] = colors_dict['Fare Zone'].map(palette)
#Output a color palette
sns.set_context('notebook')
sns.palplot(sns.color_palette("hls", colors_dict['Fare Zone'].nunique()))
plt.show()
#Same plotting attributes as before
fig, ax = plt.subplots(1, 1, figsize=(20,12))
#Same plot just now with our colors!
#Using the kamada kawai layout system
pos = nx.kamada_kawai_layout(M)
nx.draw_networkx(M, pos=pos, node_size=25, node_color=colors_dict['color'], labels=node_dict, font_size=5, ax=ax)

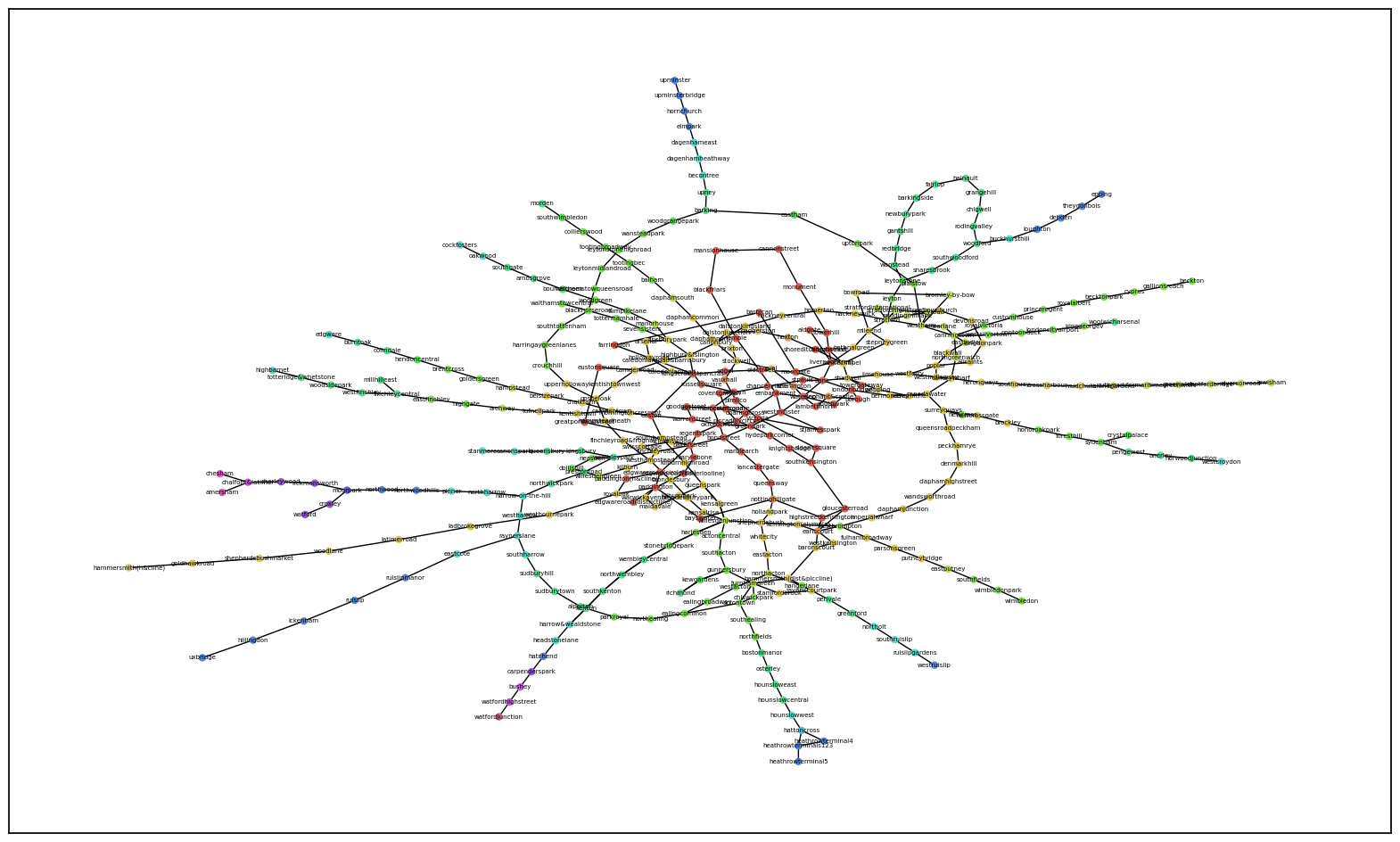
I would have expected that the red zone (Fare Zone 1) would be centralized and most connected, which appeares to be visually accurate here. However, The most interesting line to me is the yellow branch because it belongs to Fare Zone 2, yet is not as connected to other zones as you would expect for an inner zone. Other branches are very colorful, indicating that as you travel further down the branch, you travel through other zones compared to the yellow which only passes through one.
fig, ax = plt.subplots(1, 1, figsize=(20,12))
#Using our new node positions instead
nx.draw_networkx(M, pos=node_pos, node_size=25, node_color=colors_dict['color'], labels=node_dict, font_size=5, ax=ax)
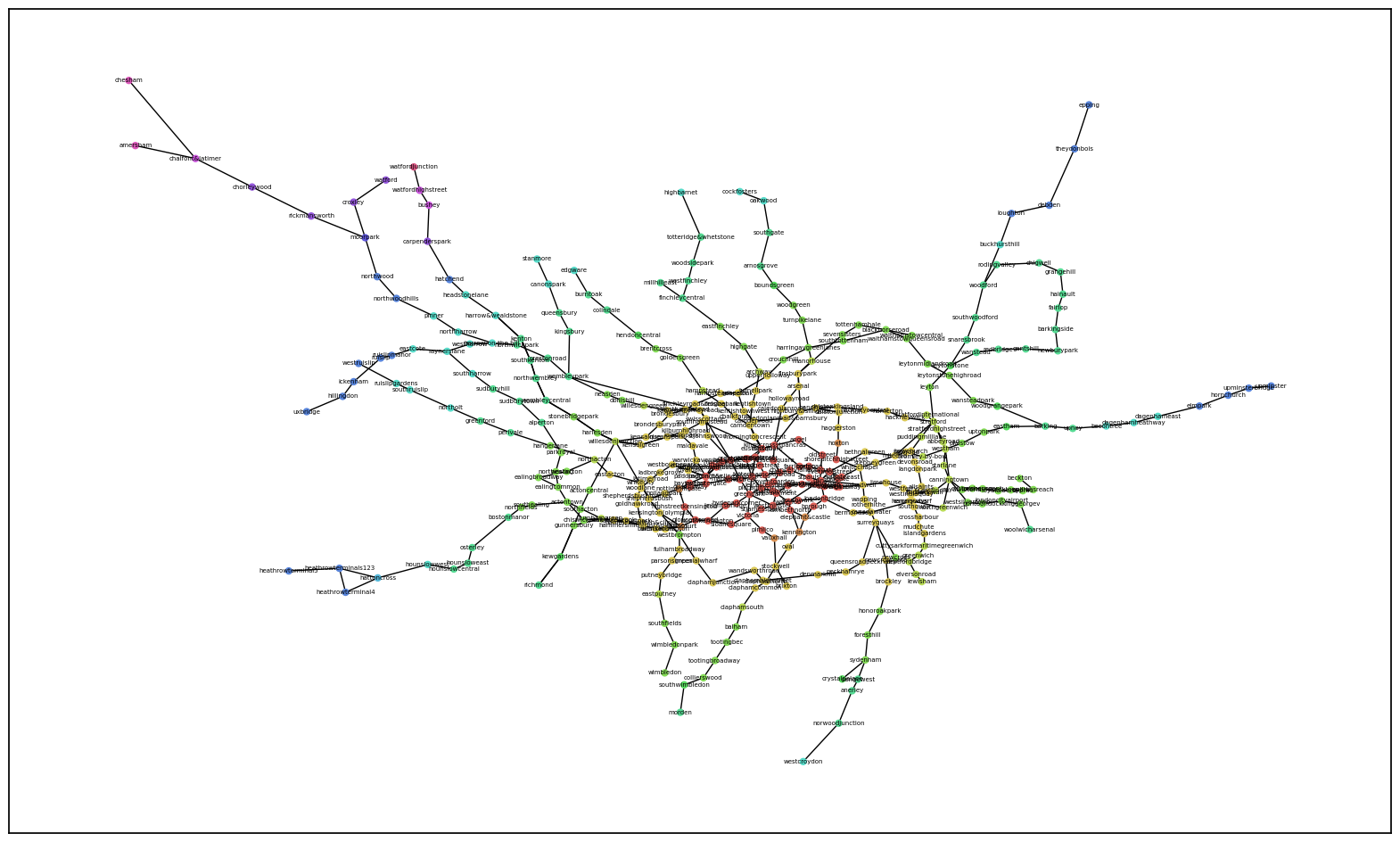
While this is more geographically accurate, there is some information lost or not translated as well since you can’t see the isolated branch of yellow as clearly. However, you can see how each zone blends into the next and forms rings.
Network Connectedness#
#Connectedness: the whole thing should be connected
print(nx.is_connected(M))
#Returns true, so we know the whole network is connected
#Since it is an undirected network, we don't need to test for weak or strong connectedness
from graspologic.utils import largest_connected_component
M_lcc = largest_connected_component(M)
print(M_lcc)
#Quick check: since the entire network is connected, the largest connected component is shown to be the entire network
True
MultiGraph with 369 nodes and 441 edges
Network Degrees#
Since we are using an undirected network, degrees are simply a count of all the edges connected to each node (we don’t need to worry about in or out degrees). In our case, it tells us how many other stations are connected to each station.
#Degrees of our network
#Function to help compare the dictionaries with outputs of the array
def map_to_nodes(node_map):
node_map.setdefault(0)
return np.array(np.vectorize(lambda x: node_map.setdefault(x, 0))(M.nodes))
#Note: If nodes are connected on multiple layers, this is also counted as well
degrees = dict((M.degree))
map_to_nodes(degrees)
array([2, 6, 2, 7, 4, 2, 5, 2, 5, 3, 4, 2, 4, 2, 2, 1, 3, 2, 2, 2, 2, 2,
2, 2, 2, 2, 4, 7, 4, 3, 2, 2, 2, 2, 6, 4, 5, 2, 2, 4, 3, 2, 2, 2,
3, 6, 2, 2, 4, 6, 2, 2, 2, 2, 2, 2, 2, 4, 2, 4, 2, 2, 4, 1, 2, 2,
2, 6, 6, 2, 3, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 4, 2, 2, 2, 2, 4, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 4, 2, 4, 5, 2, 4, 4, 2, 2, 6, 2, 2, 2,
2, 3, 2, 2, 2, 2, 2, 2, 2, 2, 3, 4, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 4, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 3, 3, 3, 2, 2, 2, 3, 2, 2, 2, 2, 2, 2, 1, 2, 2,
3, 2, 1, 2, 6, 7, 2, 3, 2, 2, 3, 4, 2, 2, 2, 2, 2, 2, 3, 2, 4, 1,
2, 2, 3, 2, 2, 1, 2, 2, 4, 3, 2, 2, 2, 2, 2, 4, 4, 4, 2, 2, 2, 7,
2, 3, 2, 3, 4, 4, 2, 3, 2, 4, 3, 2, 2, 2, 3, 2, 2, 3, 1, 2, 1, 2,
2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 4, 4, 2, 3, 2, 4,
4, 2, 2, 2, 2, 2, 1, 2, 4, 2, 2, 2, 2, 2, 2, 2, 2, 4, 2, 3, 2, 2,
2, 2, 2, 2, 3, 2, 2, 2, 1, 3, 3, 2, 2, 2, 2, 2, 2, 2, 4, 4, 2, 2,
2, 1, 2, 2, 1, 1, 3, 2, 2, 2, 2, 2, 4, 2, 2, 2, 3, 2, 2, 2, 2, 2,
2, 2, 3, 2, 2, 2, 2, 2, 4, 2, 2, 2, 2, 2, 1, 2, 1, 2, 2, 2, 2, 2,
2, 1, 2, 1, 1, 1, 2, 2, 1, 2, 1, 2, 1, 2, 1, 1, 2])
From our array, we can see a few things:
If the degree is 1, that signifies the end of the line or branch
If the degree is 2, it is contributing to an inner station of a line or branch
Anything more shows it is interconnected with other stations
Next, I wanted to look at the stations with the highest raw number of degree connections.
#This provides a sorted list of degree connections
#Borrowed from https://stackoverflow.com/questions/48382575/sort-graph-nodes-according-to-their-degree
max_degrees = sorted(M.degree, key=lambda x: x[1], reverse=True)
#I included the first 12, which includes all of the stations with both 7 and 6 connections
print(max_degrees[0:12])
[(3, 7), (27, 7), (181, 7), (219, 7), (1, 6), (34, 6), (45, 6), (49, 6), (67, 6), (68, 6), (106, 6), (180, 6)]
Top 12 Stations by Degree
7 Connections
Willesden Junction (2.5)
Baker Street (1)
Kings Cross St. Pancras (1)
Stratford (2.5)
6 Connections
Westham (2.5)
Bank (1)
Earls Court (1.5)
Paddington (1)
Green Park (1)
Oxford Circus (1)
Canning Town (2.5)
Waterloo (1)
It makes sense that the top stations would belong to zones 1 to 2.5. Interestingly enough, there are no Zone 2 stations in this list, while there are a good portion of Zone 2.5 stations. This might suggest Zone 2.5 is more interconnected or important in a sense than Zone 2. Additionally, this pairs well with our findings from the colored graph previously, where Zone 2 actually had a more isolated branch in comparison. This may have contributed to its low number of degrees or connections.
Eigenvector Centrality#
This helps us measure the influence of one train station on another, since a train station will be important if it’s connected to another important train station, and so forth.
#I used the weight to give more emphasis on LU trains with more connections
map_to_nodes(dict(nx.eigenvector_centrality(G, weight = 'weight')))
array([2.18915596e-04, 1.00237181e-03, 8.64214496e-06, 5.14846689e-05,
1.96603023e-06, 1.71870475e-06, 8.43841668e-06, 5.93121600e-02,
1.73816098e-01, 3.70525195e-02, 1.83318011e-02, 1.89639628e-05,
1.12197117e-04, 4.32794878e-09, 2.09270134e-08, 2.83220524e-12,
1.74562019e-11, 3.61090075e-10, 6.03038876e-11, 9.18253229e-02,
5.83098619e-02, 1.98045334e-04, 1.18740625e-03, 2.10257503e-06,
3.50663967e-07, 5.00651032e-03, 1.62902742e-02, 1.79655593e-01,
3.75808897e-02, 6.24504656e-02, 2.72274757e-01, 3.39549094e-02,
1.19715000e-07, 2.00561401e-08, 8.31933779e-02, 1.54069581e-02,
1.79247939e-02, 3.28347832e-01, 4.06948355e-01, 2.67462119e-01,
1.71635966e-05, 2.86999146e-06, 7.11415407e-09, 1.22217791e-09,
1.24096637e-04, 5.60684740e-04, 1.11891693e-04, 5.48332367e-03,
2.24986148e-03, 1.46445400e-02, 2.90202396e-08, 4.85723908e-09,
4.80258137e-07, 8.04459962e-08, 1.18740623e-03, 7.11918901e-03,
2.59015658e-03, 5.49592961e-04, 2.96948618e-02, 9.14113632e-03,
2.62015939e-03, 1.73903240e-03, 8.01210597e-05, 1.30014334e-05,
1.33652910e-05, 2.47494801e-05, 4.02134125e-05, 1.60587147e-02,
2.95889573e-02, 2.79582844e-03, 1.81541124e-03, 1.00534236e-08,
5.79351294e-08, 1.26065537e-05, 5.32884267e-05, 9.40110121e-06,
3.43572763e-03, 1.44110686e-03, 5.50909060e-06, 3.30312381e-05,
2.48771309e-05, 1.53028638e-04, 2.70300451e-06, 4.51209292e-07,
1.61950122e-05, 9.63569972e-04, 5.77621532e-03, 1.61978048e-04,
4.38100526e-08, 7.31884538e-09, 2.55366686e-08, 1.53235634e-07,
1.54776240e-13, 2.64081251e-14, 8.47249147e-02, 1.45614085e-02,
1.50021725e-02, 8.99445398e-02, 2.50303080e-03, 4.26833576e-02,
2.08093471e-01, 4.06954122e-02, 1.21588880e-04, 9.70426808e-05,
2.02927452e-05, 5.59364919e-05, 2.22813787e-04, 3.72037744e-05,
3.72037738e-05, 2.73009666e-03, 6.66713054e-03, 1.54339421e-02,
2.58805593e-03, 2.57568325e-03, 2.67725524e-05, 1.60652078e-04,
9.10966037e-13, 1.01928219e-10, 5.07478818e-03, 1.43268462e-02,
7.84466130e-03, 1.68218328e-02, 2.83220524e-12, 7.32441134e-09,
4.38109602e-08, 6.10788341e-10, 4.27540403e-06, 7.15179481e-07,
1.72392610e-07, 5.83790836e-07, 2.55728035e-05, 9.18815260e-07,
5.64795686e-10, 9.49145155e-11, 3.58173100e-03, 1.69415569e-02,
5.65473723e-07, 9.44204798e-08, 3.13215007e-06, 2.68878179e-06,
6.10316378e-10, 9.90194292e-11, 6.21362034e-06, 1.03812409e-06,
2.63459963e-09, 4.40321554e-10, 8.13228324e-10, 1.34935963e-08,
2.26758654e-09, 5.14434153e-04, 4.38221438e-04, 1.22313992e-09,
2.04368500e-10, 4.67770740e-07, 7.36252048e-11, 1.23091222e-11,
4.60600129e-06, 1.87426396e-04, 1.87435216e-04, 1.32302107e-07,
6.95771200e-07, 9.86641571e-04, 9.83179575e-04, 2.62021246e-06,
1.56240041e-05, 3.24012014e-07, 8.78384094e-07, 1.19701580e-07,
5.51347816e-06, 3.30319698e-05, 4.99105999e-05, 9.70642564e-08,
5.71212506e-07, 4.14353644e-09, 7.29917417e-03, 3.03372989e-02,
4.24904493e-03, 3.82038576e-10, 2.00474260e-12, 6.31944481e-03,
2.36321073e-02, 5.07534423e-01, 3.47094317e-02, 7.45838940e-02,
3.79634210e-01, 4.03161593e-10, 9.45124247e-07, 3.27000773e-02,
1.03082388e-02, 9.65316066e-04, 1.72741804e-04, 2.71706976e-03,
2.71719242e-03, 7.53887985e-08, 1.29399855e-08, 1.99950747e-05,
1.18771922e-04, 1.32699203e-10, 2.54795217e-07, 4.25526359e-08,
1.31593824e-03, 1.98045212e-04, 1.15972061e-05, 3.76411800e-06,
3.19686460e-05, 1.38281952e-02, 1.06278082e-02, 9.92516099e-05,
4.22286631e-04, 1.66136911e-05, 1.25640110e-09, 2.18072888e-09,
1.29101908e-08, 9.51634692e-03, 1.39749308e-02, 1.71616218e-06,
1.68883137e-06, 1.24756835e-04, 3.30396450e-04, 1.91034825e-03,
5.81861503e-04, 4.32798114e-05, 7.66387647e-08, 4.55930454e-07,
8.60023525e-06, 1.43724127e-06, 1.34377336e-05, 1.89655368e-10,
3.19124801e-11, 1.12932227e-09, 2.75855257e-05, 1.60787554e-04,
4.61854051e-06, 5.38320102e-12, 1.97763207e-12, 4.42700682e-13,
1.01681848e-11, 4.55980206e-13, 8.42524490e-14, 3.38721460e-06,
7.10779617e-10, 4.38068545e-09, 6.15162829e-09, 1.65480000e-08,
2.05757564e-09, 8.51112540e-02, 3.80493049e-04, 6.45403047e-11,
5.58494675e-11, 3.11632322e-10, 1.76056100e-09, 3.07012990e-03,
2.71370706e-03, 4.43791245e-08, 1.99954159e-05, 3.37648564e-06,
1.57697477e-08, 7.15075261e-04, 1.71669685e-04, 1.00633739e-03,
3.46498781e-05, 1.26205760e-04, 7.11918901e-03, 6.73491422e-09,
2.91771598e-07, 9.67700065e-04, 5.79583608e-03, 2.33892746e-04,
4.35018213e-04, 1.73382411e-07, 2.82063752e-08, 9.63292539e-04,
5.77583513e-03, 6.55180026e-04, 6.39756315e-04, 2.35824057e-04,
1.73550343e-03, 4.13286360e-03, 1.10733330e-03, 6.27831800e-03,
8.69073561e-05, 5.12606181e-03, 3.19039754e-04, 5.47700843e-05,
2.24223109e-06, 4.52150161e-07, 9.14183213e-06, 9.14162760e-06,
5.42203671e-07, 2.99466939e-03, 5.24314791e-04, 1.03810113e-06,
2.44695490e-03, 4.53179272e-04, 1.53360940e-07, 1.78055914e-02,
3.66269264e-09, 2.13537301e-08, 9.67636916e-04, 9.67457000e-08,
1.19891713e-07, 3.36428587e-07, 4.60048158e-06, 3.69629342e-10,
4.02124952e-08, 2.40320068e-07, 9.63314521e-04, 1.27947566e-07,
7.67215410e-07, 9.80839808e-12, 5.45004682e-04, 5.84393107e-08,
9.48249201e-09, 2.37636537e-03, 4.70793419e-03, 1.08977274e-02,
3.37438637e-06, 2.70584599e-06, 2.16130763e-09, 9.30188301e-04,
5.54731494e-03, 3.69894180e-04, 1.36397105e-04, 6.21361648e-06,
1.23074744e-04, 1.73518978e-07, 3.18799081e-04, 1.61954890e-05,
7.54296009e-06, 1.46529394e-07, 1.52604457e-06, 4.84551248e-08,
2.62324324e-07, 5.76722905e-04, 1.07594547e-11, 6.29213307e-11,
4.53935237e-04, 3.00317789e-03, 9.33503220e-05, 2.23213915e-03,
1.52730196e-06, 1.65715543e-08, 2.45553401e-08, 6.33889884e-03,
1.55491015e-11, 2.63485421e-06, 4.34408964e-06, 1.98977420e-04,
8.91909161e-03, 6.34471356e-03, 3.08255659e-02, 1.76105980e-04,
3.45701068e-04, 3.10146006e-04, 4.72380183e-09, 1.57560499e-05,
2.10259979e-09, 3.32627412e-11, 3.36353987e-09, 2.62875429e-08,
2.90955319e-03, 7.55849779e-05, 1.06513758e-11, 2.88004284e-06,
4.40511889e-15, 1.57626303e-07, 1.79900519e-12, 4.77050856e-10,
2.84317182e-09])
PageRank#
Note: This is a similar metric to eigenvector centrality but more suited for directed graphs. However, we can still see what it looks like and how it compares for fun.
pagerank_dict = nx.pagerank(M, max_iter=100)
np.vectorize(pagerank_dict.get)(M.nodes)
array([0.00187181, 0.00598446, 0.00187469, 0.00535295, 0.00447542,
0.00188195, 0.00420467, 0.0020055 , 0.0048308 , 0.00271507,
0.00431587, 0.00224917, 0.00388729, 0.00248894, 0.00241828,
0.00165795, 0.00442628, 0.00292196, 0.00312125, 0.00161124,
0.00158308, 0.00256193, 0.00244173, 0.00280637, 0.0029262 ,
0.00216283, 0.00405443, 0.00672253, 0.00291919, 0.00291632,
0.00362673, 0.00155711, 0.00270106, 0.0027541 , 0.00417993,
0.00334155, 0.00425365, 0.00333531, 0.00341978, 0.00462837,
0.00369536, 0.00223855, 0.00267701, 0.00268135, 0.00308995,
0.00491213, 0.00165956, 0.00297322, 0.00440111, 0.00543615,
0.0027945 , 0.00291954, 0.00246319, 0.00260128, 0.00245183,
0.00222873, 0.00194297, 0.0038878 , 0.00151387, 0.00419393,
0.00261019, 0.00265324, 0.00474074, 0.00141328, 0.00248839,
0.00211576, 0.00207794, 0.00397851, 0.00408874, 0.00187885,
0.00268972, 0.00253493, 0.00241656, 0.0027169 , 0.00235272,
0.00242289, 0.00281674, 0.00287529, 0.00273608, 0.00266806,
0.00133099, 0.00435272, 0.00256331, 0.00263215, 0.00244213,
0.00218354, 0.00401067, 0.00217706, 0.00260353, 0.002742 ,
0.00313077, 0.00293241, 0.00285307, 0.00307762, 0.001833 ,
0.00210453, 0.00216698, 0.003604 , 0.00234002, 0.00367546,
0.0050322 , 0.0017984 , 0.00386407, 0.00445432, 0.0022796 ,
0.0019998 , 0.00545239, 0.00222181, 0.0022605 , 0.00267731,
0.00268922, 0.00311549, 0.00227541, 0.00229708, 0.00297981,
0.00270803, 0.00268327, 0.00280769, 0.00185884, 0.00178863,
0.00261947, 0.0047805 , 0.00165795, 0.00262151, 0.00255287,
0.00271054, 0.00255713, 0.00263923, 0.00257707, 0.00252629,
0.00241691, 0.00281785, 0.0029383 , 0.00313514, 0.00171703,
0.00325755, 0.0025885 , 0.00265782, 0.00253574, 0.00254563,
0.0029129 , 0.0016425 , 0.00245389, 0.00259608, 0.00276032,
0.00283092, 0.0031212 , 0.00269959, 0.0027962 , 0.00232021,
0.00237102, 0.00288775, 0.00310071, 0.00257885, 0.00294073,
0.00313564, 0.00239236, 0.00240594, 0.00239727, 0.00219585,
0.00381518, 0.00383354, 0.00279285, 0.00225469, 0.0020856 ,
0.00324323, 0.00361558, 0.0030596 , 0.00267267, 0.00263252,
0.00328048, 0.00275232, 0.00262111, 0.00173589, 0.00180874,
0.00174668, 0.00262587, 0.00292041, 0.00173829, 0.00253134,
0.00473539, 0.00751093, 0.00183031, 0.00291523, 0.00354382,
0.00267578, 0.00405412, 0.00352356, 0.00191721, 0.002256 ,
0.00234752, 0.00233926, 0.00228143, 0.00267353, 0.00405328,
0.00221277, 0.00357951, 0.00173237, 0.00262738, 0.00266099,
0.00385962, 0.00258101, 0.00315095, 0.00174511, 0.00296491,
0.00166417, 0.00300353, 0.00346443, 0.00238314, 0.00246671,
0.00265745, 0.00270361, 0.00260982, 0.00272429, 0.00365164,
0.0034018 , 0.00192674, 0.00232575, 0.00214439, 0.0061734 ,
0.00222758, 0.00325051, 0.00247698, 0.00339692, 0.00292204,
0.00286375, 0.00249459, 0.00273669, 0.00224571, 0.00324134,
0.00332029, 0.00231027, 0.00211497, 0.00249978, 0.00357886,
0.0024717 , 0.0025191 , 0.00371004, 0.0014577 , 0.0024753 ,
0.00173352, 0.0031208 , 0.00320135, 0.00304132, 0.00176667,
0.00163067, 0.00175043, 0.00312193, 0.00258504, 0.00260655,
0.00259181, 0.0019646 , 0.00167833, 0.0029997 , 0.00219191,
0.00241245, 0.00271017, 0.00207481, 0.0031606 , 0.00342473,
0.00198111, 0.00248399, 0.00222453, 0.00301617, 0.00344181,
0.00227725, 0.00191159, 0.00202646, 0.00210091, 0.00302392,
0.0016906 , 0.00243653, 0.0041349 , 0.00166666, 0.00283769,
0.00283226, 0.002888 , 0.00174376, 0.00200489, 0.00187884,
0.00287094, 0.00291004, 0.00211037, 0.00336816, 0.00253125,
0.00250786, 0.00240751, 0.00245083, 0.00241592, 0.0019429 ,
0.00287063, 0.00277232, 0.00195901, 0.00251877, 0.00155449,
0.00269474, 0.00390442, 0.00262081, 0.00230805, 0.00230158,
0.00224527, 0.00219424, 0.00242735, 0.0027993 , 0.00290401,
0.00285594, 0.00226756, 0.00259924, 0.00254495, 0.00173326,
0.00188193, 0.00312601, 0.00173422, 0.00106645, 0.00300086,
0.00166406, 0.00246218, 0.00253621, 0.00279648, 0.00187378,
0.00397281, 0.00298206, 0.00306843, 0.00254692, 0.00286687,
0.00269676, 0.00215581, 0.00243033, 0.00192082, 0.00219134,
0.0025649 , 0.00186859, 0.00364574, 0.00209052, 0.00312347,
0.00292148, 0.00238251, 0.00201792, 0.00338996, 0.00262597,
0.00246207, 0.0028938 , 0.00239248, 0.00169171, 0.0017375 ,
0.00193742, 0.00167268, 0.00181464, 0.00281758, 0.00256697,
0.00179265, 0.0021271 , 0.00195151, 0.00115605, 0.00248082,
0.00135282, 0.00155483, 0.00172324, 0.00282857, 0.00292249,
0.00112958, 0.00263282, 0.00173259, 0.00221781, 0.00171353,
0.00279591, 0.0017328 , 0.001725 , 0.00310498])
Betweenness Centrality#
A station will be more important if it lies on more of the shortest paths between two stations.
map_to_nodes(nx.betweenness_centrality(M))
array([0.0005341 , 0.11306012, 0.04206423, 0.15823919, 0.08472497,
0. , 0.09691149, 0.00558733, 0.15950982, 0.00944061,
0.02121986, 0.00646215, 0.01861119, 0.01680537, 0.0196685 ,
0. , 0.01085476, 0.01083995, 0.00543478, 0.04506261,
0.04424196, 0.04264898, 0.04784682, 0.0162155 , 0.01083995,
0.00096133, 0.09555828, 0.21915044, 0.15812278, 0.06552046,
0.0456075 , 0.01145036, 0.02687774, 0.02156143, 0.23987714,
0.09794935, 0.05620178, 0.04424196, 0.04506261, 0.09139037,
0.0534562 , 0.03742151, 0.00807813, 0.00296914, 0.07523735,
0.12538745, 0. , 0.02804124, 0.03822093, 0.05936474,
0.0162155 , 0.01083995, 0.03216444, 0.02687774, 0.03742151,
0.04264898, 0.09037461, 0.14623207, 0.13889274, 0.14642559,
0.00739267, 0.00353052, 0.04703322, 0. , 0.03332089,
0.00481677, 0.00352718, 0.21981973, 0.06084849, 0.00440815,
0.00443396, 0.04264898, 0.04784682, 0.02156143, 0.00518734,
0.00199423, 0.00347263, 0.00104771, 0.02156143, 0.02687774,
0. , 0.05620878, 0.04264898, 0.03742151, 0.04784682,
0.03680002, 0.06513122, 0.03429241, 0.02156143, 0.0162155 ,
0.00543478, 0.01083995, 0.01083995, 0.00543478, 0.00664589,
0.00220205, 0.01617055, 0.15122751, 0.01215324, 0.10453442,
0.20672303, 0. , 0.11374946, 0.10480792, 0.04784682,
0.06423371, 0.10400317, 0.03742151, 0.02156143, 0.00227414,
0.00425244, 0.05378806, 0.00821287, 0.04010338, 0.00543478,
0.01083995, 0.0162155 , 0.0162155 , 0.00996944, 0.0100815 ,
0.00544024, 0.02303976, 0. , 0.0083743 , 0.01363138,
0.02156143, 0.03742151, 0.03216444, 0.05155604, 0.05232535,
0.04264898, 0.0162155 , 0.01083995, 0.00543478, 0.0008145 ,
0.01570612, 0.03742151, 0.03216444, 0.01091202, 0.00895061,
0.00543478, 0. , 0.03216444, 0.02687774, 0.02156143,
0.0162155 , 0.00543478, 0.02156143, 0.0162155 , 0.00618449,
0.03821281, 0.01083995, 0.00543478, 0.05212229, 0.01083995,
0.00543478, 0.00270075, 0.0005183 , 0.00146853, 0.00748332,
0.03379055, 0.08343277, 0.02049499, 0.04434383, 0.04864822,
0.02687774, 0.05351349, 0.02156143, 0.03216444, 0.03742151,
0.03998994, 0.0162155 , 0.02156143, 0. , 0.0011884 ,
0.00400204, 0.03419872, 0.01083995, 0. , 0.01263494,
0.22548276, 0.2233532 , 0.10319098, 0.04734002, 0.04605014,
0.00045166, 0.02693697, 0.17714428, 0.00051337, 0.02402932,
0.02157522, 0.03742151, 0.0474565 , 0.03216444, 0.02693697,
0.03216444, 0.08868952, 0. , 0.0184442 , 0.01322414,
0.08551586, 0.03216444, 0.00543478, 0. , 0.01083995,
0.00059457, 0.01013742, 0.02577279, 0.01043773, 0.01536079,
0.00311723, 0.02156143, 0.02687774, 0.00747733, 0.19579813,
0.04197624, 0.03789609, 0.03712971, 0.036896 , 0.20093409,
0.00583971, 0.07239478, 0.03216444, 0.04551371, 0.06326265,
0.05815365, 0.00985838, 0.03216444, 0.02687774, 0.03742151,
0.11188557, 0.10813157, 0.05224364, 0.02156143, 0.0162155 ,
0. , 0.02156143, 0.00543478, 0. , 0.04264898,
0. , 0.00543478, 0.00543478, 0.01083995, 0. ,
0.00735906, 0.01441743, 0.00543478, 0.02687774, 0.03216444,
0.03742151, 0.00742237, 0.02877463, 0.0162155 , 0.05586832,
0.05384669, 0.02687774, 0.02779218, 0.09462435, 0.10167802,
0.03381577, 0.05953509, 0.05301505, 0.04264898, 0.00543478,
0.00635539, 0.10070189, 0.00444082, 0.00295151, 0.00543478,
0. , 0.0162155 , 0.14504712, 0.02590915, 0.02687774,
0.02156143, 0.03216444, 0.00244153, 0.01324162, 0.01612191,
0.0162155 , 0.00326946, 0.0981963 , 0.09382034, 0.03067013,
0.02856741, 0.05502162, 0.02895836, 0.02710763, 0.02591299,
0.02272666, 0.01083995, 0.00500182, 0.03216444, 0. ,
0.00891661, 0.0375696 , 0.04264898, 0.00445494, 0.00934353,
0.02387293, 0.05301505, 0.05815365, 0.0162155 , 0.04784682,
0.05301505, 0.11239647, 0.04784682, 0.05301505, 0. ,
0.01073896, 0.00543478, 0. , 0. , 0.03805088,
0.01588279, 0.02687774, 0.05394556, 0.0162155 , 0.03642193,
0.09048895, 0.04925474, 0.04449868, 0.0162155 , 0.00597995,
0.02156143, 0.0101828 , 0.05652326, 0.00150458, 0.02286571,
0.02370128, 0. , 0.04528492, 0.00482385, 0.00543478,
0.01083995, 0.04276956, 0.00751015, 0.09946098, 0.06095182,
0.04991263, 0.01083995, 0.01968431, 0.02887472, 0. ,
0.00073492, 0. , 0. , 0.00870175, 0.02111882,
0.0018984 , 0.03328866, 0.00205012, 0. , 0.01707552,
0. , 0. , 0. , 0.0162155 , 0.01083995,
0. , 0.02687774, 0. , 0.02642396, 0. ,
0.0162155 , 0. , 0. , 0.00543478])
Plotting Centrality Measures (Multigraph Attempt)#
#Plotting and comparing different connectedness measures
from graspologic.plot import networkplot
from matplotlib import colors
multi_data = pd.DataFrame(index=M.nodes())
#Adjusting the x and y to be longitude and latitude
multi_data['x'] = multi_data.index.map(node_data[' nodeLong'])
multi_data['y'] = multi_data.index.map(node_data[' nodeLat'])
multi_data["degree"] = multi_data.index.map(dict(nx.degree(M)))
multi_data["eigenvector"] = multi_data.index.map(nx.eigenvector_centrality(G, weight = 'weight'))
multi_data["pagerank"] = multi_data.index.map(nx.pagerank(M))
multi_data["betweenness"] = multi_data.index.map(nx.betweenness_centrality(M))
fig, axs = plt.subplots(1, 4, figsize=(20, 5))
def plot_node_scaled_network(A, node_data, key, ax):
# REF: https://github.com/mwaskom/seaborn/blob/9425588d3498755abd93960df4ab05ec1a8de3ef/seaborn/_core.py#L215
levels = list(np.sort(node_data[key].unique()))
#Changed color palette for more contrast
cmap = sns.color_palette('Reds', as_cmap=True)
vmin = np.min(levels)
norm = colors.Normalize(vmin=0.3 * vmin)
palette = dict(zip(levels, cmap(norm(levels))))
networkplot(
A,
node_data=node_data,
x='x',
y='y',
ax=ax,
edge_linewidth=1.0,
node_size=key,
node_hue=key,
palette=palette,
#Scaled down node sizes by a factor of 2 so it's less clumped
node_sizes=(10, 100),
node_kws=dict(linewidth=1, edgecolor="black"),
node_alpha=1.0,
edge_kws=dict(color=sns.color_palette()[0])
)
ax.axis("off")
ax.set_title(key.capitalize())
ax = axs[0]
plot_node_scaled_network(A, multi_data, "degree", ax)
ax = axs[1]
plot_node_scaled_network(A, multi_data, "eigenvector", ax)
ax = axs[2]
plot_node_scaled_network(A, multi_data, "pagerank", ax)
ax = axs[3]
plot_node_scaled_network(A, multi_data, "betweenness", ax)
fig.set_facecolor("w")
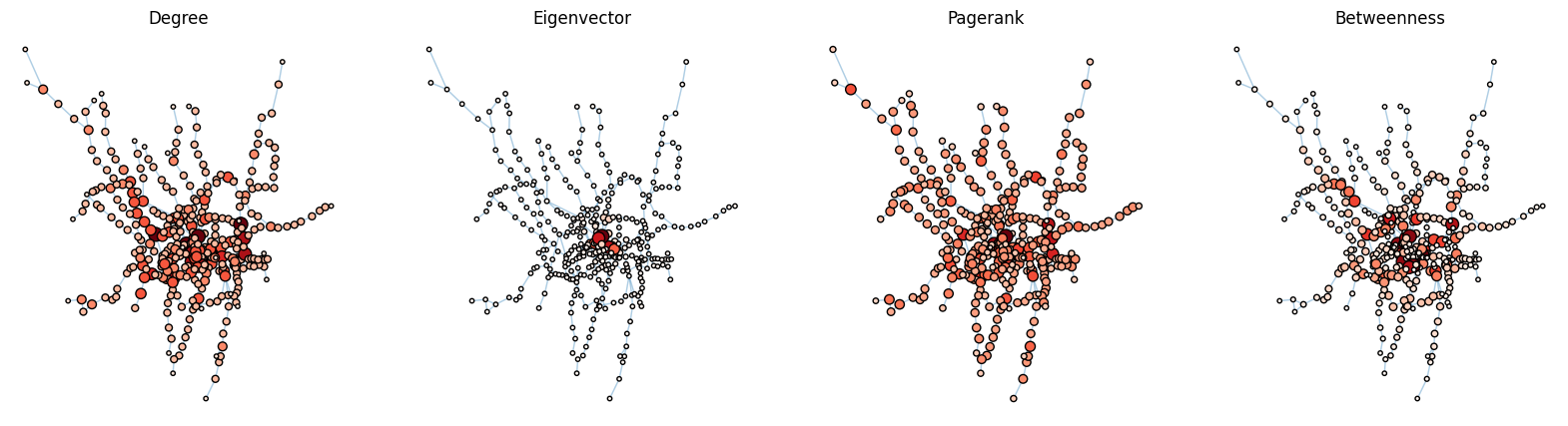
#View tabular node centrality measure data
#Reverse sort to view the properties of nodes with the highest degree
print(multi_data.sort_values(by='degree', ascending=False))
x y degree eigenvector pagerank betweenness
181 -0.123858 51.530312 7 5.075344e-01 0.007511 0.223353
3 -0.243895 51.532234 7 5.148467e-05 0.005353 0.158239
27 -0.156890 51.523130 7 1.796556e-01 0.006723 0.219150
219 -0.003737 51.541693 7 1.910348e-03 0.006173 0.200934
1 0.005332 51.528526 6 1.002372e-03 0.005984 0.113060
.. ... ... ... ... ... ...
173 -0.275079 51.614230 1 4.143536e-09 0.001736 0.000000
294 -0.209881 51.608317 1 1.533609e-07 0.001554 0.000000
141 -0.417256 51.657605 1 9.901943e-11 0.001643 0.000000
80 -0.114538 51.462737 1 2.487713e-05 0.001331 0.000000
244 -0.477087 51.546455 1 2.057576e-09 0.001767 0.000000
[369 rows x 6 columns]
#See the correlation between each degree measure
sns.pairplot(multi_data, vars=['degree', 'eigenvector', 'pagerank', 'betweenness'], height=4)
<seaborn.axisgrid.PairGrid at 0x7fcff12b53d0>
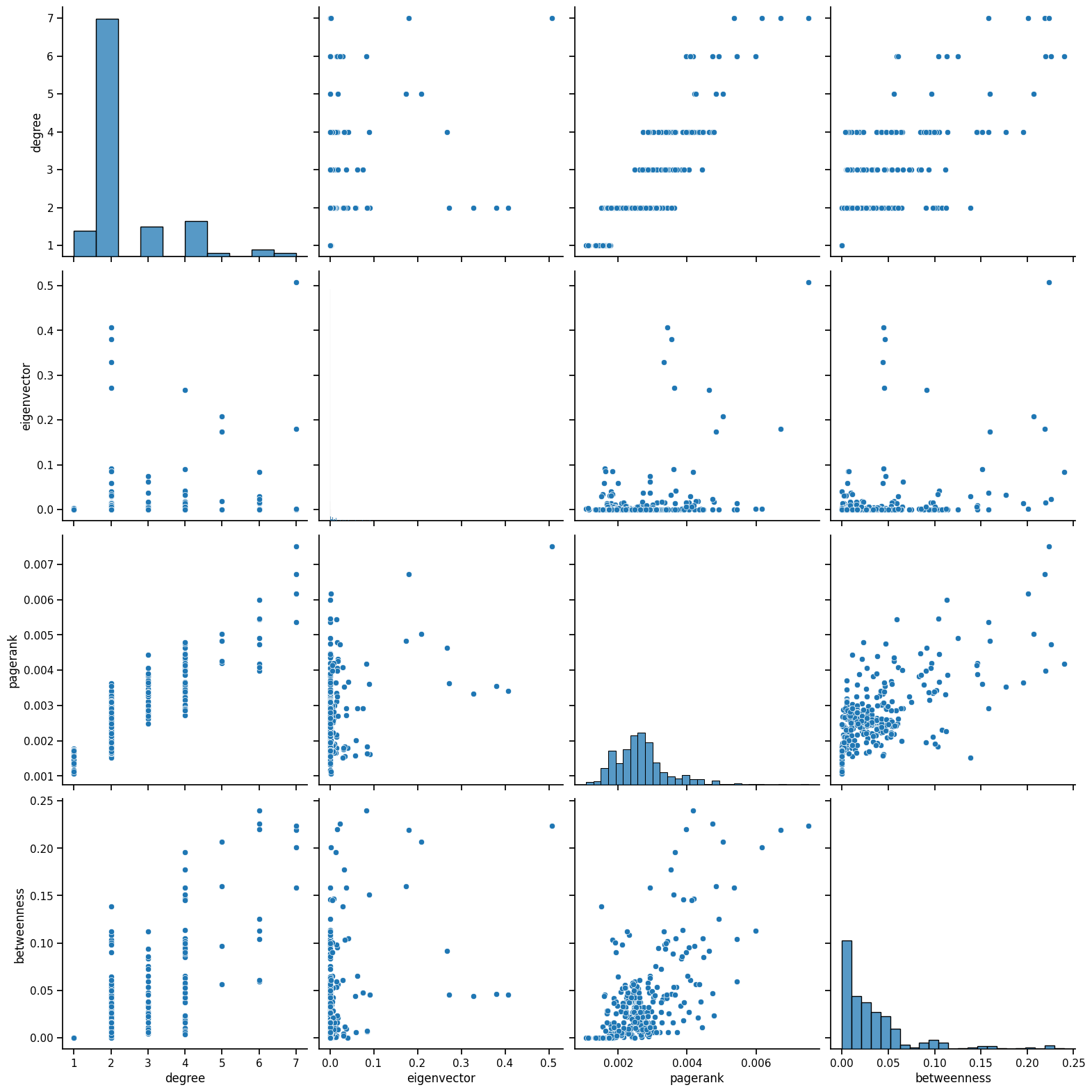
It was at this point that I realized it would not be effective to use a multigraph network in combination with eigenvector centrality measures, since we are not sure what it assumes about our data. Also, eigenvector centrality would not run with a multigraph network, so I had to use my original network with some weighting parameters, but inherently makes the graphs unequal because they are using slightly different networks. Later, I will fix this by using a simpler network and compressing some of our data to ensure at least we know what the centrality measures are doing to our data, so we have a more accurate interpretation.
Random Network Models (SBM)#
#Considering our non-weighted network
from graspologic.plot import heatmap
#Plot function
def plot_model_and_sample(estimator, name):
fig, axs = plt.subplots(1,2,figsize=(20,10), sharey=True)
heatmap(
estimator.p_mat_,
#inner_hier_labels=labels,
vmin=0,
vmax=1,
font_scale=1.5,
title=f"{name} probability matrix",
sort_nodes=False,
ax=axs[0]
)
ax = heatmap(
estimator.sample()[0],
#inner_hier_labels=labels,
font_scale=1.5,
title=f"{name} sample",
sort_nodes=False,
ax=axs[1],
)
#fig.axes[5].remove()
#SBM
from graspologic.models import SBMEstimator
#Not directed so we set it to be false
sbme = SBMEstimator(directed=False, loops=False)
#Using our original adjacency matrix
sbme.fit(A)
print('SBM "B" matrix:')
print(sbme.block_p_)
plot_model_and_sample(sbme, 'SBM')
SBM "B" matrix:
[[3.07692308e-02 1.06837607e-02 1.24069479e-02 2.17706821e-03
0.00000000e+00 2.56410256e-02 0.00000000e+00 0.00000000e+00
2.43427459e-04]
[1.06837607e-02 2.15179969e-02 0.00000000e+00 2.09643606e-03
0.00000000e+00 2.31481481e-03 0.00000000e+00 0.00000000e+00
2.81293952e-03]
[1.24069479e-02 0.00000000e+00 4.51612903e-02 2.43457091e-03
0.00000000e+00 3.76344086e-02 1.61290323e-02 5.91397849e-02
0.00000000e+00]
[2.17706821e-03 2.09643606e-03 2.43457091e-03 2.90275762e-02
9.43396226e-02 0.00000000e+00 0.00000000e+00 2.20125786e-02
3.58251732e-04]
[0.00000000e+00 0.00000000e+00 0.00000000e+00 9.43396226e-02
6.66666667e-01 0.00000000e+00 0.00000000e+00 0.00000000e+00
0.00000000e+00]
[2.56410256e-02 2.31481481e-03 3.76344086e-02 0.00000000e+00
0.00000000e+00 0.00000000e+00 3.33333333e-01 0.00000000e+00
0.00000000e+00]
[0.00000000e+00 0.00000000e+00 1.61290323e-02 0.00000000e+00
0.00000000e+00 3.33333333e-01 0.00000000e+00 0.00000000e+00
0.00000000e+00]
[0.00000000e+00 0.00000000e+00 5.91397849e-02 2.20125786e-02
0.00000000e+00 0.00000000e+00 0.00000000e+00 4.00000000e-01
0.00000000e+00]
[2.43427459e-04 2.81293952e-03 0.00000000e+00 3.58251732e-04
0.00000000e+00 0.00000000e+00 0.00000000e+00 0.00000000e+00
1.07232121e-02]]
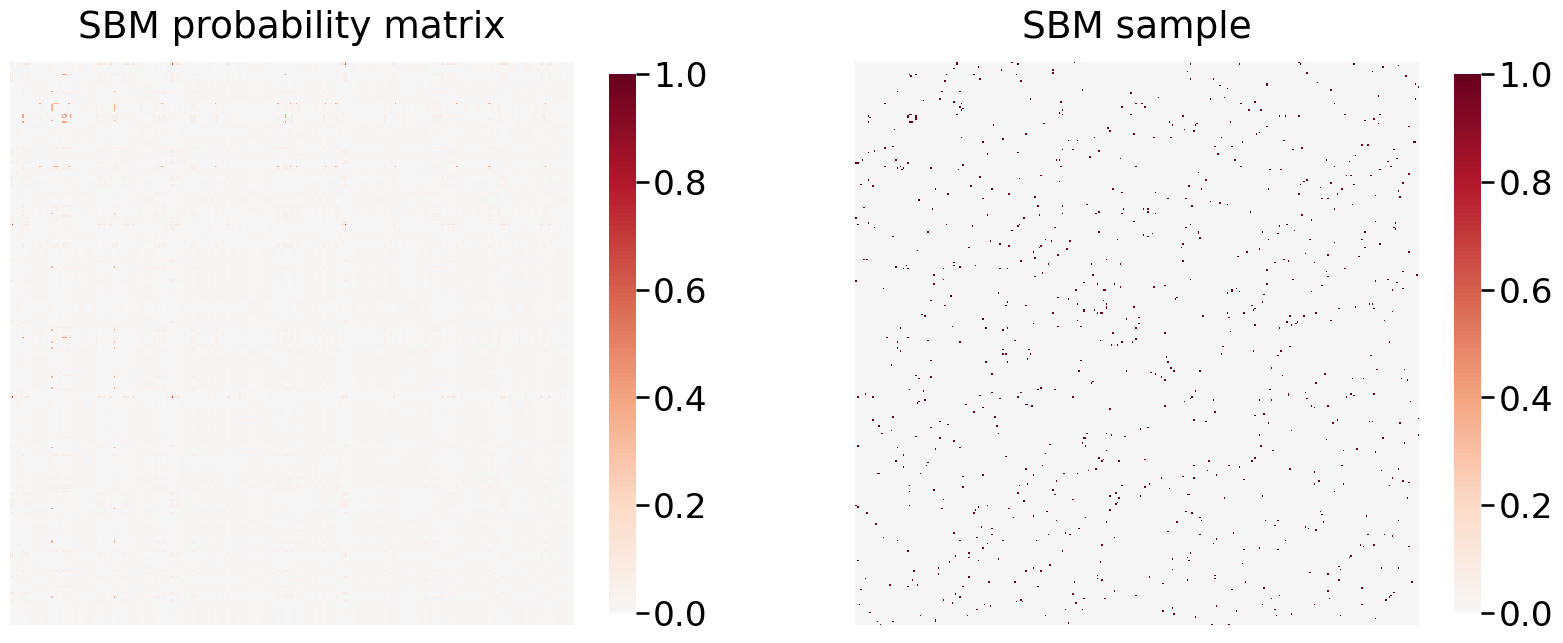
As you can see, this does not give us a particularly clear view of any of the data or insights since the dataset is so sparse, so I will avoid generating more block models for this data.
Modularity#
We can measure how strong communities are within our train network. I anticipate it will be somewhat high because nodes or stations that are associated with each other will likely have more connections, while they will interact to a minimal degree with any other station.
from graspologic.partition import leiden, modularity
from graspologic.plot import heatmap
#Since leiden only supports non-multigraph networks, I will use G
#I will use 100 trials since Leiden is a non-deterministic algorithm
leiden_partition_map = leiden(G, trials=100)
print(leiden_partition_map)
{153: 1, 143: 10, 324: 0, 321: 11, 322: 11, 98: 2, 210: 13, 113: 6, 251: 6, 4: 4, 195: 5, 42: 13, 196: 5, 62: 2, 333: 0, 225: 14, 241: 8, 220: 6, 284: 2, 202: 16, 212: 12, 275: 16, 326: 0, 362: 11, 340: 13, 25: 2, 45: 5, 100: 8, 323: 6, 152: 13, 67: 7, 355: 1, 189: 16, 209: 2, 248: 4, 244: 12, 296: 17, 37: 2, 39: 2, 59: 6, 358: 3, 27: 16, 121: 7, 140: 17, 316: 5, 117: 17, 246: 5, 115: 16, 328: 4, 367: 5, 188: 16, 83: 1, 339: 7, 353: 6, 366: 12, 267: 15, 279: 5, 219: 6, 94: 2, 254: 5, 313: 16, 2: 15, 357: 13, 35: 7, 183: 7, 299: 12, 327: 1, 110: 6, 23: 18, 112: 6, 95: 2, 139: 2, 158: 16, 205: 7, 71: 4, 174: 16, 87: 15, 300: 12, 64: 2, 207: 2, 228: 14, 325: 10, 337: 0, 289: 0, 76: 6, 175: 16, 19: 2, 238: 4, 179: 7, 108: 6, 73: 18, 22: 8, 20: 2, 61: 6, 81: 7, 265: 16, 101: 8, 148: 11, 107: 10, 171: 5, 44: 5, 122: 17, 102: 0, 105: 0, 119: 7, 239: 9, 310: 5, 82: 1, 47: 5, 214: 7, 350: 16, 149: 6, 120: 7, 151: 13, 21: 8, 169: 8, 172: 5, 341: 5, 221: 4, 68: 7, 261: 5, 131: 8, 96: 2, 103: 1, 266: 15, 126: 3, 242: 12, 276: 16, 320: 7, 280: 16, 330: 13, 78: 8, 14: 12, 315: 16, 13: 12, 213: 7, 264: 15, 31: 16, 74: 0, 34: 7, 348: 6, 343: 7, 147: 11, 291: 6, 301: 4, 354: 12, 156: 0, 138: 2, 314: 16, 281: 7, 141: 17, 145: 9, 215: 15, 272: 16, 292: 15, 72: 4, 80: 7, 66: 0, 193: 1, 236: 4, 331: 15, 9: 6, 53: 11, 288: 11, 150: 6, 136: 9, 258: 15, 345: 4, 142: 10, 227: 14, 243: 12, 332: 13, 344: 3, 192: 2, 283: 13, 304: 14, 338: 5, 11: 0, 260: 15, 128: 1, 5: 4, 161: 5, 160: 12, 123: 13, 157: 16, 363: 11, 163: 5, 18: 1, 203: 16, 235: 4, 88: 13, 346: 16, 144: 9, 230: 17, 335: 12, 41: 11, 361: 18, 305: 14, 270: 6, 187: 16, 85: 15, 182: 15, 77: 6, 0: 6, 48: 5, 50: 10, 224: 14, 116: 14, 154: 9, 217: 6, 106: 6, 1: 6, 7: 6, 347: 6, 124: 13, 36: 0, 52: 11, 336: 2, 223: 12, 190: 16, 282: 13, 118: 7, 268: 15, 285: 2, 75: 0, 307: 17, 257: 7, 3: 15, 226: 2, 317: 1, 253: 12, 16: 17, 165: 12, 349: 7, 133: 3, 198: 13, 99: 8, 312: 18, 318: 1, 55: 8, 63: 2, 278: 5, 91: 8, 271: 16, 216: 15, 199: 13, 56: 0, 57: 0, 256: 9, 255: 5, 298: 16, 218: 6, 234: 4, 135: 7, 168: 8, 173: 8, 43: 13, 247: 11, 293: 18, 84: 1, 58: 6, 204: 16, 302: 17, 306: 17, 273: 7, 97: 2, 181: 2, 30: 16, 286: 13, 170: 11, 356: 1, 250: 4, 229: 14, 303: 12, 8: 6, 17: 1, 167: 12, 274: 16, 51: 10, 54: 8, 93: 14, 86: 16, 180: 7, 90: 8, 295: 6, 125: 17, 222: 12, 70: 7, 329: 12, 206: 7, 197: 10, 186: 8, 240: 8, 29: 16, 262: 8, 134: 7, 365: 8, 28: 7, 185: 13, 60: 7, 208: 2, 127: 3, 49: 16, 231: 17, 6: 4, 311: 18, 146: 10, 69: 7, 334: 12, 287: 13, 201: 8, 259: 15, 351: 7, 130: 3, 297: 17, 263: 14, 12: 0, 294: 8, 360: 0, 65: 0, 32: 3, 111: 6, 211: 12, 245: 7, 359: 8, 159: 12, 368: 5, 191: 18, 178: 9, 114: 16, 290: 0, 184: 2, 364: 14, 104: 9, 252: 7, 194: 1, 109: 6, 92: 14, 249: 4, 308: 17, 89: 13, 38: 2, 233: 14, 155: 9, 342: 12, 129: 1, 132: 3, 319: 7, 200: 7, 15: 17, 137: 9, 237: 4, 232: 12, 177: 11, 46: 5, 10: 6, 164: 5, 26: 2, 79: 8, 269: 6, 166: 12, 176: 7, 33: 3, 162: 5, 24: 18, 309: 1, 40: 11, 277: 7, 352: 6}
nx.set_edge_attributes(G, 1, 'weight')
#Calculate modularity
modularity(G, leiden_partition_map)
0.8343591130340726
Our modularity score is relatively high, and this would make sense because stations that form in communities are likely to have the strongest connections within their own community, and interact far less with others.
Community Detection#
How can we divide our train network into communities that make sense?
We will use the Leiden algorithm.
#Plotting our community partitions generated with Leiden
#Credit to: https://bdpedigo.github.io/networks-course/community_detection.html#agglomerative-optimization-louvain-leiden
def plot_network_partition(adj, node_data, partition_key):
fig, axs = plt.subplots(1, 2, figsize=(15, 7))
networkplot(
adj,
x='x',
y='y',
node_data=node_data.reset_index(),
node_alpha=0.9,
edge_alpha=0.7,
edge_linewidth=0.4,
node_hue=partition_key,
node_size="degree",
edge_hue="source",
ax=axs[0],
#tab20 to prevent more communities than colors
palette='tab20'
)
axs[0].axis("off")
heatmap(
adj,
inner_hier_labels=node_data[partition_key],
ax=axs[1],
cbar=False,
cmap="Reds",
vmin=0,
center=None,
sort_nodes=True,
hier_label_fontsize=8
)
return fig, ax
#Use our original multi_data pandas dataframe
multi_data['leiden_partition'] = multi_data.index.map(leiden_partition_map)
#Use our original unweighted adjacency matrix A
plot_network_partition(A, multi_data, 'leiden_partition')
(<Figure size 1500x700 with 4 Axes>,
<AxesSubplot: title={'center': 'Betweenness'}>)
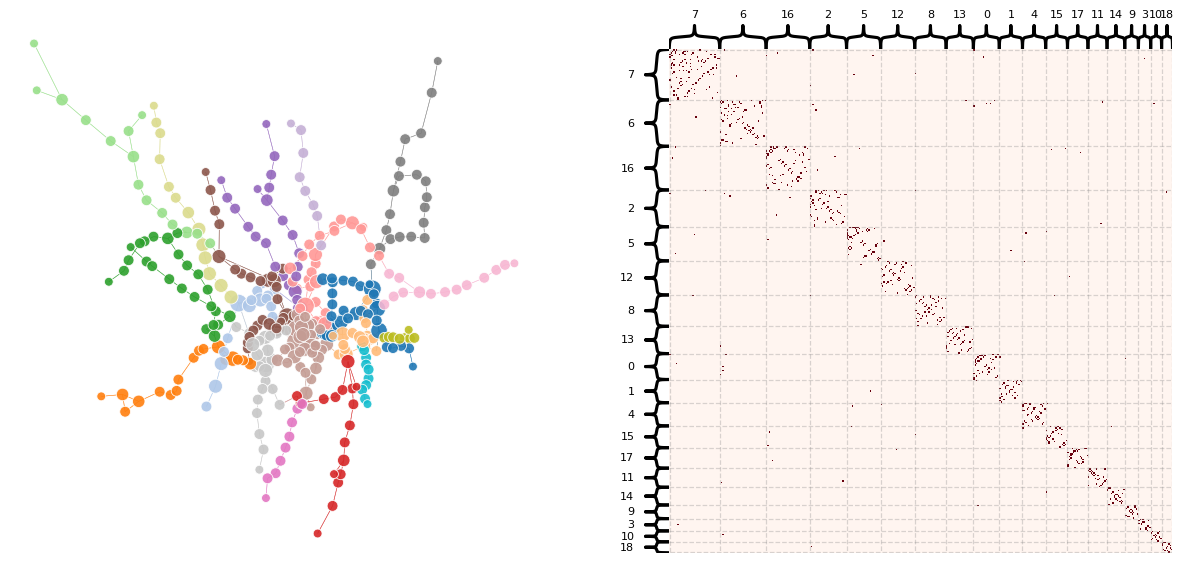
From this Leiden graph, the algorithm seems to have created communities related to the branches, or more specifically, the lines of our train network. This would make sense because communities would be likely to form where there are connections with each other, and that’s exactly where some lines are located. Considering fare zone, this makes the center of the graph interesting since there are multiple intersecting lines passing through Zone 1.
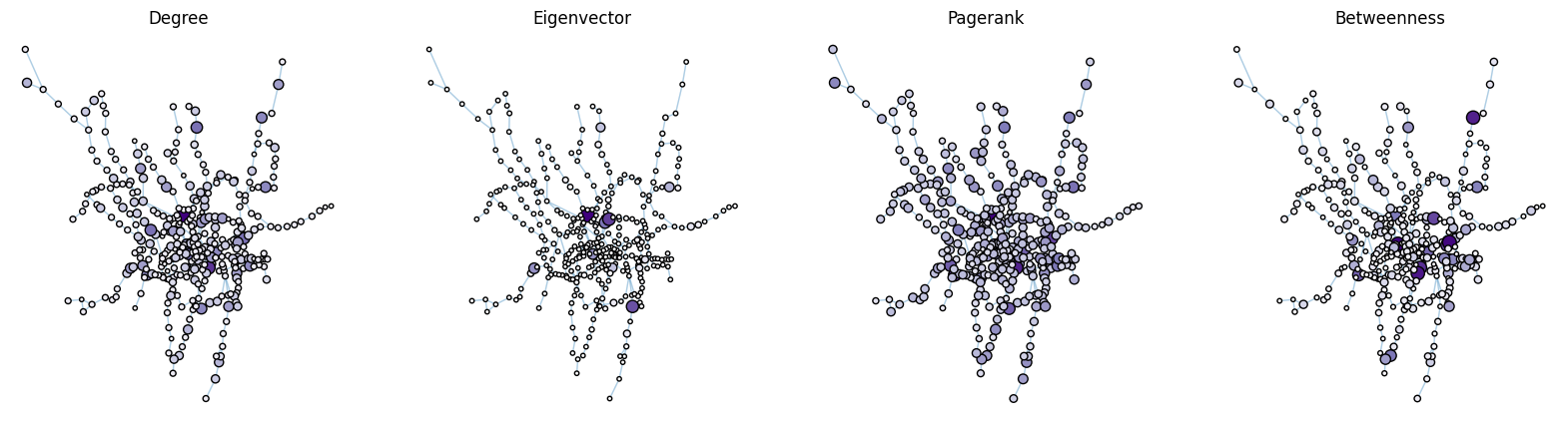
Plotting Centrality Measures (Weighted Graph)#
‘Weight’ now means if a station has a non-1 weight, it connects a station to another station on either multiple layers and/or it has an underground connection with multiple lines. More simply, it is the sum of all of the weights connecting to or from that particular node.
#Weighted Graph: A more aggregate view
#Constructed from our mulitgraph data
W = nx.Graph()
for u,v,data in M.edges(data=True):
w = data['weight'] if 'weight' in data else 1.0
if W.has_edge(u,v):
W[u][v]['weight'] += w
else:
W.add_edge(u, v, weight=w)
This looks a bit different than what we saw earlier, because now we are including the weights in each one which inflates our degree count technically. For instance, 181 (King’s Cross St Pancras) has a degree of 12, which is much larger than the degree of 7 it had before.
import pandas as pd
weighted_data = pd.DataFrame(index=W.nodes())
#Adjust the x and y again to account for our long and lat
weighted_data['x'] = multi_data.index.map(node_data[' nodeLong'])
weighted_data['y'] = multi_data.index.map(node_data[' nodeLat'])
weighted_data["degree"] = weighted_data.index.map(dict(nx.degree(W, weight = 'weight')))
weighted_data["eigenvector"] = weighted_data.index.map(nx.eigenvector_centrality(W, weight='weight'))
weighted_data["pagerank"] = weighted_data.index.map(nx.pagerank(W, weight='weight'))
#Weight correlates to distance? Not sure if that is right
weighted_data["betweenness"] = weighted_data.index.map(nx.betweenness_centrality(W, weight='weight'))
fig, axs = plt.subplots(1, 4, figsize=(20, 5))
def plot_node_scaled_network(A, node_data, key, ax):
# REF: https://github.com/mwaskom/seaborn/blob/9425588d3498755abd93960df4ab05ec1a8de3ef/seaborn/_core.py#L215
levels = list(np.sort(node_data[key].unique()))
#Changed color palette for more contrast
cmap = sns.color_palette('Purples', as_cmap=True)
vmin = np.min(levels)
norm = colors.Normalize(vmin=0.3 * vmin)
palette = dict(zip(levels, cmap(norm(levels))))
networkplot(
A,
node_data=node_data,
x="x",
y="y",
ax=ax,
edge_linewidth=1.0,
node_size=key,
node_hue=key,
palette=palette,
#Scaled down node sizes by a factor of 2 so it's less clumped
node_sizes=(10, 100),
node_kws=dict(linewidth=1, edgecolor="black"),
node_alpha=1.0,
edge_kws=dict(color=sns.color_palette()[0])
)
ax.axis("off")
ax.set_title(key.capitalize())
ax = axs[0]
plot_node_scaled_network(A, weighted_data, "degree", ax)
ax = axs[1]
plot_node_scaled_network(A, weighted_data, "eigenvector", ax)
ax = axs[2]
plot_node_scaled_network(A, weighted_data, "pagerank", ax)
ax = axs[3]
plot_node_scaled_network(A, weighted_data, "betweenness", ax)
fig.set_facecolor("w")
sns.pairplot(weighted_data, vars=['degree', 'eigenvector', 'pagerank', 'betweenness'], height=4)
<seaborn.axisgrid.PairGrid at 0x7fd011de1490>
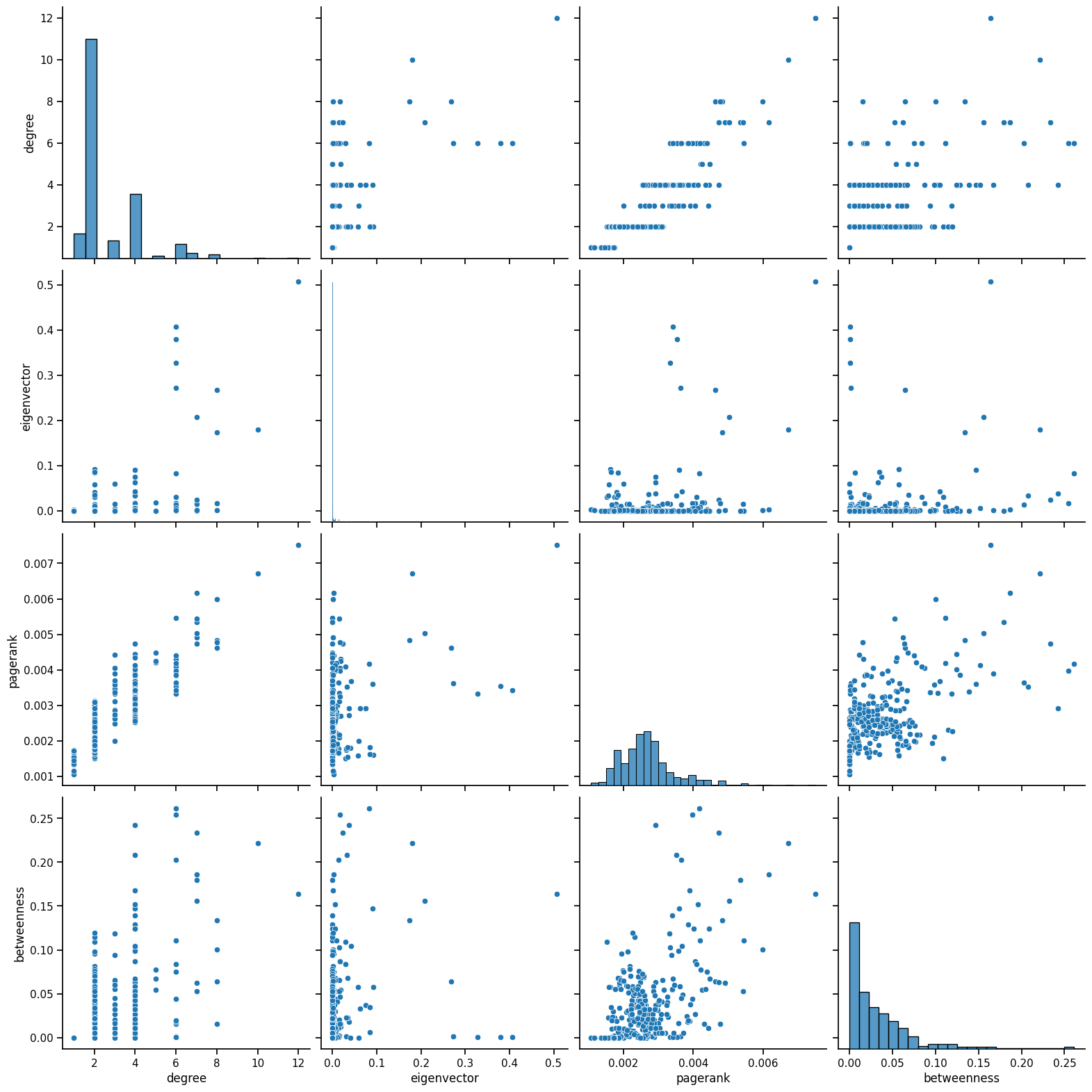
What is happening here?
Degree: Very discrete because degree only ranges from 1 to 12, which is why there are vertical lines. There is some positive correlation between degree and pagerank, indicating that in general, stations that have more links to other stations will have a greater importance, which is expected.
Betweenness: There is also some weak relation with pagerank. With a low betweenness score or influence on travel in the network, most nodes tend to have a low pagerank, and that would make sense considering most nodes only connect to two other stations, before and after them in the line. Thus, they would not have a large pagerank since the node would have low importance. It is interesting how the pagerank varies as betweenness increases, indicating that some nodes that connect multiple stations and affect travel, are not as important as others.
Comparing Stations#
Now, let’s compare direct stations based on their centrality measure values.
d = weighted_data.sort_values(by='degree', ascending=False)
e = weighted_data.sort_values(by='eigenvector', ascending=False)
p = weighted_data.sort_values(by='pagerank', ascending=False)
b = weighted_data.sort_values(by='betweenness', ascending=False)
#Print out the 20 nodes with the highest degrees and eigenvectors
print(d.iloc[0:10,2])
print(e.iloc[0:10,3])
181 12
27 10
1 8
8 8
39 8
121 8
3 7
219 7
45 7
180 7
Name: degree, dtype: int64
181 0.507534
38 0.406948
184 0.379634
37 0.328347
30 0.272275
39 0.267461
100 0.208094
27 0.179656
8 0.173816
19 0.091825
Name: eigenvector, dtype: float64
#Print out the 20 nodes with the highest pagerank and betweenness
print(p.iloc[0:10,4])
print(b.iloc[0:10,5])
181 0.007511
27 0.006723
219 0.006173
1 0.005984
106 0.005452
49 0.005436
3 0.005353
100 0.005032
45 0.004912
8 0.004831
Name: pagerank, dtype: float64
34 0.261068
67 0.254292
28 0.242083
180 0.233240
27 0.221704
187 0.207972
214 0.203039
219 0.186174
3 0.179475
57 0.167474
Name: betweenness, dtype: float64
rankings = {'rank': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
'degree': ['Kings Cross', 'Baker Street', 'Westham', 'Liverpool Street', 'Moorgate', 'Embankment', 'Willesden Junction', 'Stratford', 'Earls Court', 'Waterloo'],
'eigenvec': ['Kings Cross', 'Farringdon', 'Euston Square', 'Barbican', 'Great Portland Street', 'Moor Gate', 'Euston', 'Baker Street', 'Liverpool Street', 'Angel'],
'pagerank': ['Kings Cross', 'Baker Street', 'Stratford', 'Westham', 'Canning Town', 'Paddington', 'Willesden Junction', 'Euston', 'Earlscourt', 'Liverpool Street'],
'betweenness': ['Bank', 'Greenpark', 'Bondstreet', 'Waterloo', 'Baker Street', 'Finchley Road', 'Westminster', 'Stratford', 'Willesden Junction', 'Canada Water'],
'foot traffic': ['Kings Cross', 'Victoria', 'Oxford Circus', 'London Bridge', 'Waterloo', 'Stratford', 'Liverpool Street', 'Paddington', 'Canary Wharf', 'Bank']
}
pd.DataFrame(data = rankings)
| rank | degree | eigenvec | pagerank | betweenness | foot traffic | |
|---|---|---|---|---|---|---|
| 0 | 1 | Kings Cross | Kings Cross | Kings Cross | Bank | Kings Cross |
| 1 | 2 | Baker Street | Farringdon | Baker Street | Greenpark | Victoria |
| 2 | 3 | Westham | Euston Square | Stratford | Bondstreet | Oxford Circus |
| 3 | 4 | Liverpool Street | Barbican | Westham | Waterloo | London Bridge |
| 4 | 5 | Moorgate | Great Portland Street | Canning Town | Baker Street | Waterloo |
| 5 | 6 | Embankment | Moor Gate | Paddington | Finchley Road | Stratford |
| 6 | 7 | Willesden Junction | Euston | Willesden Junction | Westminster | Liverpool Street |
| 7 | 8 | Stratford | Baker Street | Euston | Stratford | Paddington |
| 8 | 9 | Earls Court | Liverpool Street | Earlscourt | Willesden Junction | Canary Wharf |
| 9 | 10 | Waterloo | Angel | Liverpool Street | Canada Water | Bank |
Note: I included the top 10 busiest stations based on foot traffic data from https://en.wikipedia.org/wiki/List_of_busiest_London_Underground_stations as a comparison metric. Most stations on the foot traffic list make an appearance in our centrality lists, however a few don’t, namely, Victoria, Oxford Circus, London Bridge, and Canary Wharf. This suggests there might be another factor that isn’t based on the connectedness or node importance that causes this discrepency.
Adjusted Rand Score#
This is a similarity measure used to determine if the labels are completely random (0) or are completely identical (1). I will use the leiden communities we generated earlier along with the fare zone information to determine if they have any correlation.
from sklearn.metrics import adjusted_rand_score
#Make a node list
nodes = M.nodes
#Assign the two labels
labels1 = [leiden_partition_map[node] for node in nodes]
labels2 = [node_fare_dict[node] for node in nodes]
adjusted_rand_score(labels1, labels2)
0.11597731607181089
This is a low adjusted rand score, which tells us that our leiden communities are not very correlated with our fare zones. This would also make sense based on our information earlier, which showed leiden communities that seemed to be more associated with lines rather than the circular zones.
Future Considerations#
Here are some ideas for extending or improving upon this project.
Lines: I did not have time to look at and incorporate line information for each station, but this could be a good metric to run our Leiden communiites against to see how correlated those labels are.
Foot traffic: Additionally, there is detailed data available for each station and how many entries or exits there are: https://en.wikipedia.org/wiki/List_of_busiest_London_Underground_stations. This information might align well with our centrality measures if incorporated more thoroughly as a node attribute.
Labelling: My data did not come with an alphabetic station code (ASC), so I just used the original node names. However, for clarity in graphing, it may be helpful to add a node attribute with the ASC to avoid any possible confusion. For any additional data, it will help adding information that is not sorted the same way as the original file since it will likely come sorted by ASC and not the station name.
Prediction: Using an algorithm to predict where the next train station should be built based on community detection and trying to maximize the connectedness of the overall network. This can also be based on location data or other logistical constraints.
Comparison: Comparing the London transport system with that of another country and interpreting certain other metrics. (Ex. NYC doesn’t have fare zones, but what would that look like if we tried to construct some?)